MongoDB-Sharding
Sharding
Mongodb sharding is based on shard key.
K1 -> k2 on shard1 K2 -> k3 on shard2 etc..
Each shard is then replicated for higher availability and DR etc..Sharding is therefore range based. Sharding is done per collections basis.Range based sharding helps it do range based queries.
All of the documents on a particular shard are known as chunks ~~ 100mb.
There are two operations that happen in the background in sharding and these are done automatically for us.
- Split - splits a range if the range is producing bigger chunks, this is fairly expensive
- Migrate - moves chunks to somewhere else in the cluster, this is somewhat expensive.
- Between a pair of shards there will not be more than one migration activity.
- We can still read and write from the data when we are migrating. So, it is live.
- "Balancer" decides when to do the balancing. It balances on the number of chunks today.
Both of these are done to maintain a balance in the shards w.r.t. the documents. The metadata about these shards and our system is stored in config servers. These are light weight. Conceptually these shards are processes and not separate physical machines or virtual machines although they can and most likely will be.
Mongos gives the client the big picture of the whole setup. Client is therefore insulated from the underlying architecture that is used to implement sharding, replication etc..
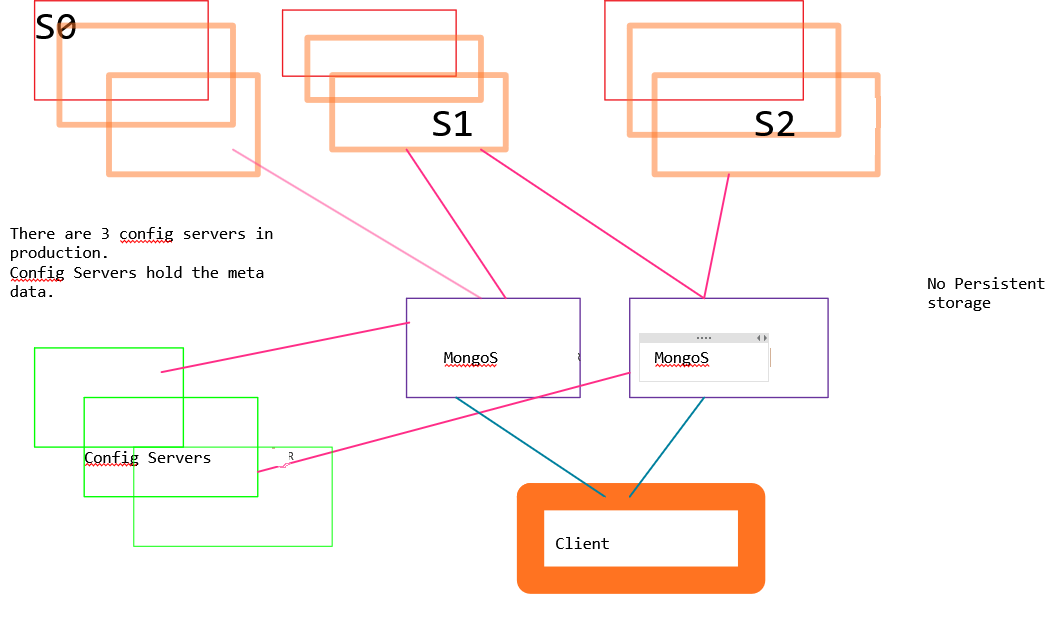
End client applications should go through mongos.
To create a shard connect to mongos
Then
sh.addShard("hostname:port")
sh.enableSharding("dbname")
db.ensureIndex(Key pattern for your shard key)
sh.shardCollection("namespaceforyourCollection",shardkey);
Choosing a shard key
- Filed should be involved in most of the queries
- Good cardinality/granularity
- Shard key should not increase monotonically